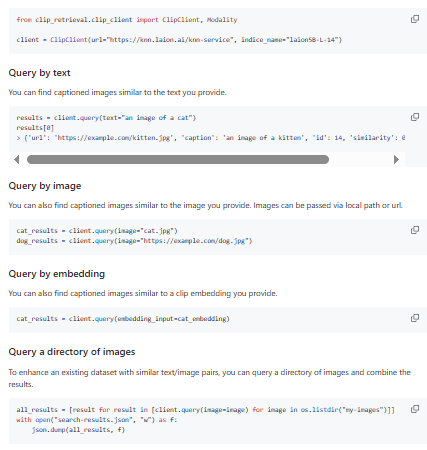
clip-retrieval is an open-source toolkit designed to build large-scale semantic search systems for images and text by leveraging CLIP embeddings to enable multimodal retrieval. It allows developers to compute embeddings for both images and text efficiently and then index them for fast similarity search across massive datasets. The system is optimized for performance and scalability, capable of processing tens or even hundreds of millions of embeddings using GPU acceleration. It includes components for inference, indexing, filtering, and serving results through APIs, making it a complete pipeline for building production-ready retrieval systems. The framework also supports querying by image, text, or embedding, enabling flexible use cases such as reverse image search or multimodal content discovery. Additionally, it provides a simple frontend interface and backend services that can be deployed to expose search functionality to users.
Features
- High-speed embedding computation for text and images
- Scalable indexing for millions or billions of data points
- Multimodal search using image text or embeddings
- REST API backend for serving search queries
- End-to-end pipeline from dataset to deployed search system
- GPU acceleration for high performance processing
Project Samples