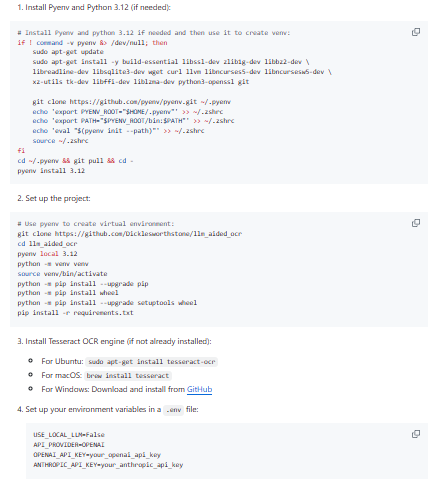
LLM Aided OCR is an open-source system designed to improve optical character recognition accuracy by combining traditional OCR tools with large language models. The project addresses common OCR challenges such as distorted text, unusual fonts, historical documents, and complex layouts that often produce inaccurate results with standard OCR pipelines. The system first extracts raw text using OCR engines and then applies language models to analyze and correct recognition errors based on context. This AI-assisted correction process helps reconstruct missing characters, fix formatting mistakes, and produce more coherent text outputs. The project is particularly useful for digitizing historical documents, research papers, and scanned materials where traditional OCR often struggles. It also includes tools for processing batches of images or documents, enabling automated document digitization workflows.
Features
- Integration of OCR engines with large language models for error correction
- Context-aware reconstruction of distorted or incomplete text
- Improved recognition accuracy for historical and low-quality documents
- Batch processing tools for digitizing large document collections
- Support for scanned images and complex page layouts
- Automated post-processing pipeline that refines OCR output
Project Samples