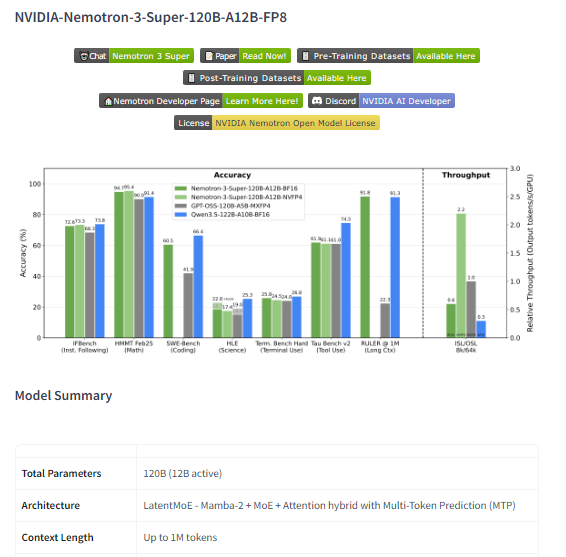
NVIDIA-Nemotron-3-Super-120B-A12B-FP8 is a large-scale open language model developed by NVIDIA as part of the Nemotron-3 family of generative AI systems designed for advanced reasoning, conversational interaction, and agent-based workflows. The model contains approximately 120 billion parameters, but employs a Mixture-of-Experts architecture that activates only a smaller subset of parameters during inference, improving computational efficiency while maintaining high capability. Its architecture combines Transformer attention layers with Mamba state-space components to balance long-context reasoning, memory efficiency, and high-quality language generation. The model is optimized for building AI agents that must perform complex tasks such as planning, tool usage, coding assistance, and multi-step reasoning.
Features
- Hybrid Mixture-of-Experts architecture combining Transformer and Mamba components
- Large-scale model with roughly 120B parameters and about 12B active during inference
- Extremely long context window enabling analysis of large documents and conversations
- Configurable reasoning mode that can produce explicit reasoning traces
- Designed for AI agents, RAG pipelines, and enterprise automation systems
- High-throughput inference optimized for large-scale workloads
Project Samples