Qwen3-VL
Qwen3-VL is the newest vision-language model in the Qwen family (by Alibaba Cloud), designed to fuse powerful text understanding/generation with advanced visual and video comprehension into one unified multimodal model. It accepts inputs in mixed modalities, text, images, and video, and handles long, interleaved contexts natively (up to 256 K tokens, with extensibility beyond). Qwen3-VL delivers major advances in spatial reasoning, visual perception, and multimodal reasoning; the model architecture incorporates several innovations such as Interleaved-MRoPE (for robust spatio-temporal positional encoding), DeepStack (to leverage multi-level features from its Vision Transformer backbone for refined image-text alignment), and text–timestamp alignment (for precise reasoning over video content and temporal events). These upgrades enable Qwen3-VL to interpret complex scenes, follow dynamic video sequences, read and reason about visual layouts.
Learn more
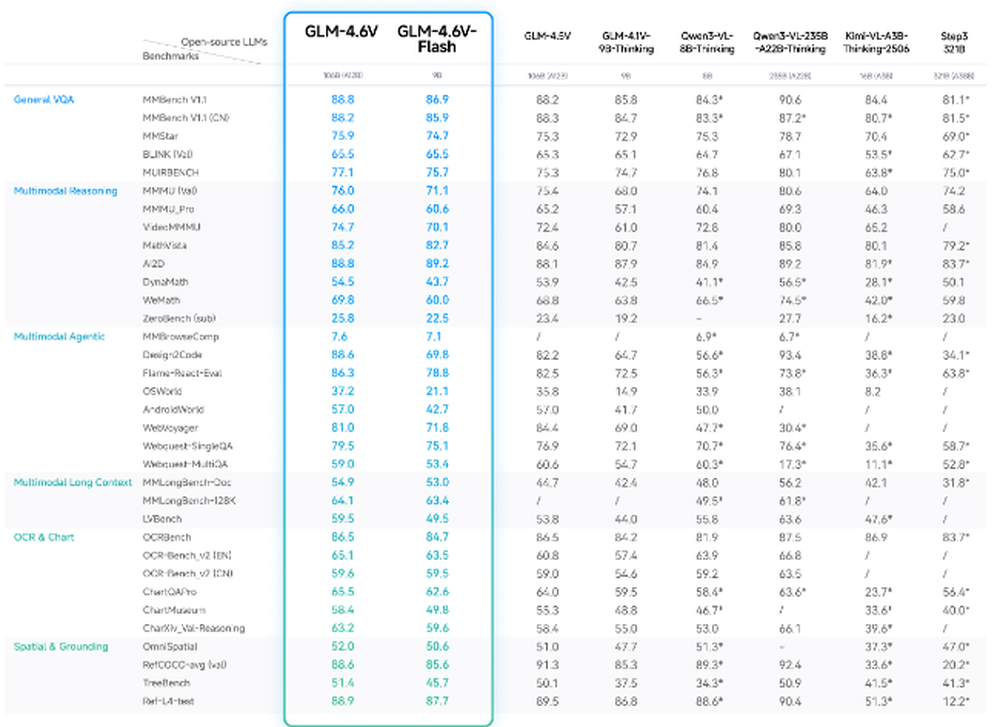
GLM-4.5V-Flash
GLM-4.5V-Flash is an open source vision-language model, designed to bring strong multimodal capabilities into a lightweight, deployable package. It supports image, video, document, and GUI inputs, enabling tasks such as scene understanding, chart and document parsing, screen reading, and multi-image analysis. Compared to larger models in the series, GLM-4.5V-Flash offers a compact footprint while retaining core VLM capabilities like visual reasoning, video understanding, GUI task handling, and complex document parsing. It can serve in “GUI agent” workflows, meaning it can interpret screenshots or desktop captures, recognize icons or UI elements, and assist with automated desktop or web-based tasks. Although it forgoes some of the largest-model performance gains, GLM-4.5V-Flash remains versatile for real-world multimodal tasks where efficiency, lower resource usage, and broad modality support are prioritized.
Learn more
GLM-5V-Turbo
GLM-5V-Turbo is a multimodal coding foundation model designed for vision-based coding tasks, capable of natively processing inputs such as images, video, text, and files while producing text outputs. It is optimized for agent workflows, enabling a full loop of understanding environments, planning actions, and executing tasks, and integrates seamlessly with agent frameworks like Claude Code and OpenClaw. It supports long-context interactions with a context length of 200K tokens and up to 128K output tokens, making it suitable for complex, long-horizon tasks. It offers multiple thinking modes for different scenarios, strong vision comprehension across images and video, real-time streaming output for improved interaction, and advanced function-calling capabilities for integrating external tools. It also includes context caching to enhance performance in extended conversations. In practical use, it can reconstruct frontend projects from design mockups.
Learn more
GLM-4.1V
GLM-4.1V is a vision-language model, providing a powerful, compact multimodal model designed for reasoning and perception across images, text, and documents. The 9-billion-parameter variant (GLM-4.1V-9B-Thinking) is built on the GLM-4-9B foundation and enhanced through a specialized training paradigm using Reinforcement Learning with Curriculum Sampling (RLCS). It supports a 64k-token context window and accepts high-resolution inputs (up to 4K images, any aspect ratio), enabling it to handle complex tasks such as optical character recognition, image captioning, chart and document parsing, video and scene understanding, GUI-agent workflows (e.g., interpreting screenshots, recognizing UI elements), and general vision-language reasoning. In benchmark evaluations at the 10 B-parameter scale, GLM-4.1V-9B-Thinking achieved top performance on 23 of 28 tasks.
Learn more